MobileNetV2: Inverted Residuals and Linear Bottlenecks
原文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks
摘要
In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. is based on an inverted residual structure where the shortcut connections are between the thin bottleneck layers. The intermediate expansion layer uses lightweight depthwise convolutions to filter features as a source of non-linearity. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on ImageNet [1] classification, COCO object detection [2], VOC image segmentation [3]. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as actual latency, and the number of parameters.
在本文中,我们描述了一种新的移动体系结构MobileNetV2,它改进了移动模型在多个任务和基准上以及不同模型大小范围内的最新性能。我们还描述了如何将这些移动模型应用于一个新的目标检测框架,我们称之为SSDLite。此外,我们还演示了如何通过一个DeepLabv3简化版(称之为移动版DeepLabv3)来构建移动语义分割模型
MobileNetV2基于反向残差结构,在两个很小(通道数很少)的bottleneck层之间执行残差连接。中间扩展层使用轻量级深度卷积来过滤非线性特征。此外,我们发现为了保持表达能力,消除窄层中的非线性操作是很重要的。我们证明这样操作能提高性能,并说明实现这种设计的直觉
最后,我们的方法允许输入/输出域与转换的表达性分离,这为进一步的分析提供了一个方便的框架。我们在ImageNet[1]分类、COCO目标检测[2]、PASCAL VOC图像分割[3]上评估算法性能。我们评估了准确度和乘-加法(MAdd)运算数量之间的权衡,以及实际延迟和参数数量
章节内容
论文在MobileNetV1的基础上,对每层的激活特征图(文中称为mainifold of interest - 兴趣流形)进行了研究,提出了一个具有线性瓶颈层的反向残差块,最终实现了MobileNetV2。论文实现流程如下:
- 首先介绍了
MobileNetV2中使用的各个关键模块,包括深度可分离卷积、线性瓶颈层、反向残差块 - 其次介绍了
MobileNetV2模型的整体架构和实现 - 最后通过实验证明
MobileNetV2在目标识别、检测(提出了SSDLite)、分割方面的进步
瓶颈残差块
MobileNetV1主要使用了深度可分离卷积层进行构建,V2在此基础上进一步研究如何更好的传递信息,提出了线性瓶颈层和反向残差块的概念,最后组合成瓶颈残差块(bottleneck residual block)
Linear Bottleneck
在卷积模型的计算过程中,输出特征图的空间大小不断的被压缩;同时在MobileNetV1中,使用宽度乘法器还可以减少通道数,这说明图像特征(称之为manifold of interest,兴趣流形)位于低维子空间中,随着卷积的计算,兴趣流形会逐渐扩充到整个空间
但是在实际计算过程中,往往在卷积层之后添加非线性激活函数,比如ReLU,非线性激活函数在引入非线性特征的同时会不可避免的造成信息的损失。论文在补充材料中证明了将低维兴趣流形嵌入到高维空间中,再执行ReLU,这样能够保留更多的特征
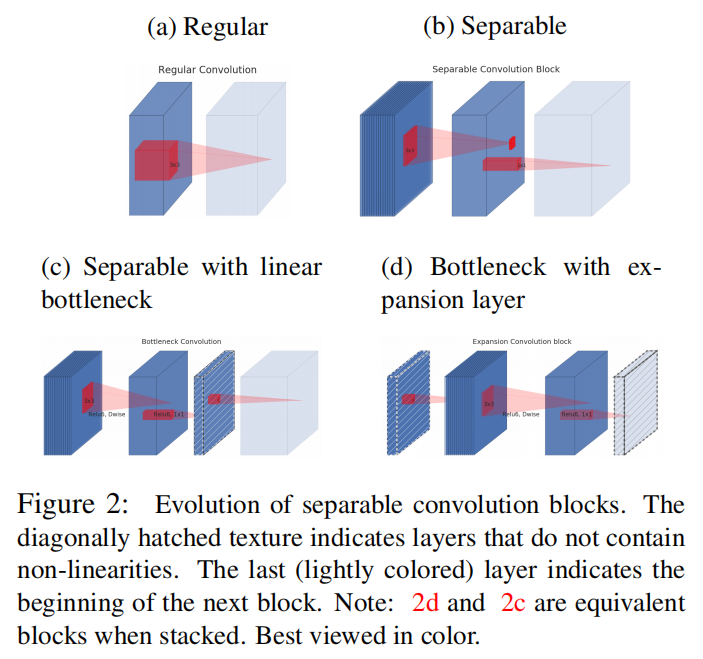
如上图d所示,在深度可分离卷积层之前插入一个线性瓶颈层(linear bottleneck layer)。先将输入特征图进行维度扩充,同时在这一过程中不执行ReLU操作。对于线性瓶颈层的输入输出数据的维度比率,使用超参数\(t\)表示,称之为扩张率(expansion ratio)
Inverted residuals
论文还引入了残差思想,在两个线性瓶颈层输入数据之间执行快捷连接
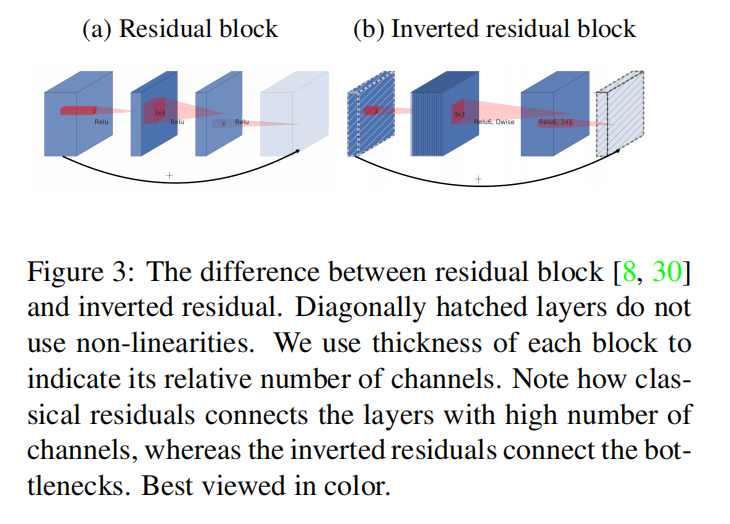
在残差块中,使用\(1\times 1\)卷积先进行降维再升维;而论文使用\(1\times 1\)卷积先进行升维再降维,所以称之为反向残差(inverted residual)
ReLU6
ReLU6对ReLU的输出进行了限制,其最大输出值为6,适用于移动端低精度设备
\[ ReLU6(x) = min(max(0, x), 6) \]
论文说ReLU6出现在MobileNetV1论文上,查看了很久都没有发现,估计出现在了源码中
小结
完整的瓶颈残差块实现如下:
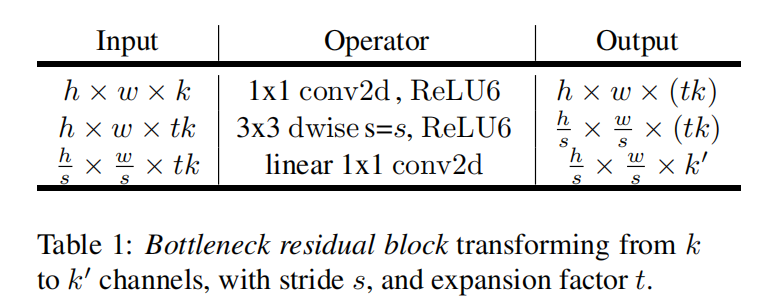
论文在实际实现过程中,先使用\(1\times 1\)卷积进行升维(使用了ReLU6),然后使用\(3\times 3\)深度卷积进行过滤,最后使用\(1\times 1\)线性卷积进行降维
和上面的实现有点差别,线性瓶颈层使用在了结束而不是开始。类似于图2(c)所示
模型架构
整体架构

t:扩展率c:通道数n:重复次数s:步长
每一行表示一个或多个相同参数的层,参数s适用于每一个行的第一个层,其余层的步长为1;使用\(3\times 3\)卷积核进行空间过滤
关于扩张率,论文发现在5到10之间的扩展率会产生几乎相同的性能曲线,较小的网络在扩展率稍小的情况下会更好,较大的网络在扩展率稍大的情况下会有稍好的性能
stride=1/2
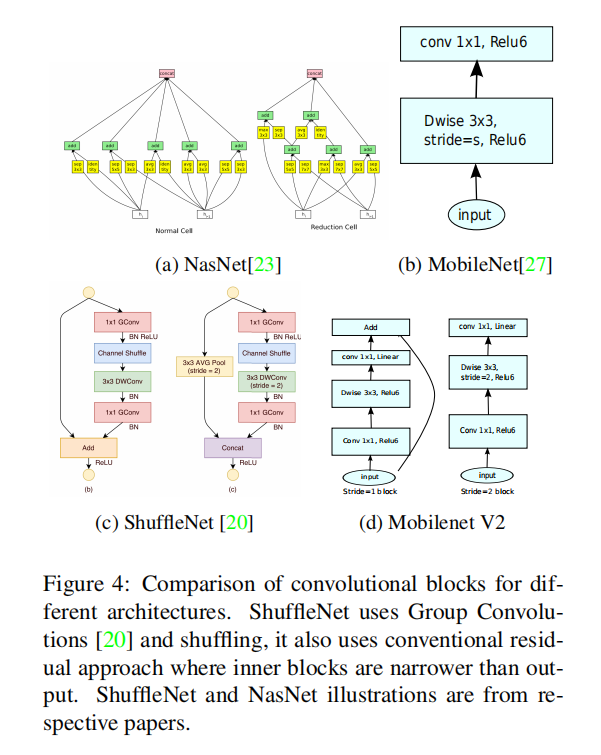
当stride=1时,瓶颈残差块使用了残差连接
实验
训练细节
- 优化器:
RMPSProp.衰减和动量大小为0.9 - 权重衰减:
4e-5 - 学习率调度:初始学习率为
4.5e-3,每轮衰减率0.98 - 批量大小:
96 GPU数目:16
SSDLite
对SSD进行了修改,使用MobileNetV2作为特征提取层,同时将预测层的标准卷积替换为深度可分离卷积,称该变体为SSDLite
具体实现参考:object-detection-algorithm/SSD
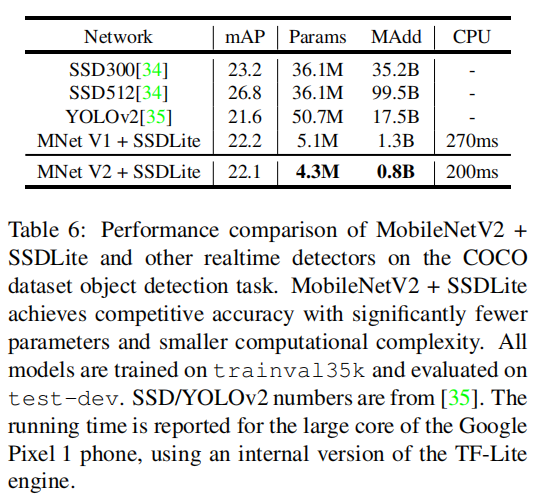
相比于SSD和YOLOv2,相近检测精度的情况下,MobileNetV2 SSDLite实现了20倍的速度提升和10倍的模型减小
小结
MobileNetV2最重要的贡献在于实现了一个新的模块 - 瓶颈残差块。其首先将输入的低维压缩信息扩展到高维空间,然后通过一个轻量级深度卷积进行过滤,最后使用线性瓶颈层投影回低维空间