Learning Spatiotemporal Features with 3D Convolutional Networks
原文地址:Learning Spatiotemporal Features with 3D Convolutional Networks
官方实现:C3D: Generic Features for Video Analysis
复现地址:ZJCV/C3D
摘要
We propose a simple, yet effective approach for spatiotemporal feature learning using deep 3-dimensional convolutional networks (3D ConvNets) trained on a large scale supervised video dataset. Our findings are three-fold: 1) 3D ConvNets are more suitable for spatiotemporal feature learning compared to 2D ConvNets; 2) A homogeneous architecture with small 3x3x3 convolution kernels in all layers is among the best performing architectures for 3D ConvNets; and 3) Our learned features, namely C3D (Convolutional 3D), with a simple linear classifier outperform state-of-the-art methods on 4 different benchmarks and are comparable with current best methods on the other 2 benchmarks. In addition, the features are compact: achieving 52.8% accuracy on UCF101 dataset with only 10 dimensions and also very efficient to compute due to the fast inference of ConvNets. Finally, they are conceptually very simple and easy to train and use.
我们提出了一种简单而有效的时空特征学习方法,该方法使用在大规模有监督视频数据集上训练的深度三维卷积网络(3D-ConvNets)。我们的研究结果有三个方面:1)三维ConvNets比二维ConvNets更适合时空特征学习;2) 在所有层中设置卷积核为3x3x3大小的统一架构是3D网络的最佳性能体系结构之一;3)我们学习的特征,即C3D(卷积3D),用一个简单的线性分类器,在4个不同的基准上优于最先进的方法,在其他2个基准上与当前最好的方法相当。此外,该模型计算得到的特征具有结构紧凑性:仅使用10维向量即可在UCF101数据集上获得了52.8%的准确率,并且由于ConvNets的快速推理能力,计算效率也很高。最后,它们在概念上非常简单,易于训练和使用。

3D卷积
相比于2D卷积操作,3D卷积操作天然的能够计算输入数据的时空特征。其实现如下图所示

- 对于
2D卷积而言,其输入不论是一张图像(单通道)还是多张图像(可视为多通道),其输出均为一张图像(特征图,视为单通道图像); - 而对于
3D卷积而言,其输出是一个3D卷,保留了输入信号的时间特征。
卷积核大小
在2D卷积网路中,\(3\times 3\)大小的卷积核已被验证拥有最好的性能;论文在此基础上探索了时间维度的最佳设置
常用术语
- 输入视频片段大小为\(c\times l\times h\times w\),其中,\(c\)表示通道数,\(l\)表示帧数,\(h\times w\)表示\(长\times 宽\);
- 3D卷积核以及Pool核大小为\(d\times k\times k\),其中,\(d\)表示时间维度大小,\(k\)表示空间维度大小
通用架构
- 数据集
- 使用
UCF101作为训练/测试数据集; - 输入分辨率大小设置为\(128\times 171\);
- 每个视频被分离为不重叠的
16帧视频片段; - 进行随机裁剪,得到最后的输入大小为\(3\times 16\times 112\times 112\);
- 使用
- 模型
- 共
5个卷积层和池化层(每个卷积层之后有一个池化层); - 卷积层的滤波器个数分别为\(64/128/256/256/256\);
- 卷积池化操作后跟随
2个全连接层和一个softmax分类器;
- 共
- 卷积核
- 卷积核的空间维度(宽和高)设置为\(3\times 3\),时间维度设置为\(d\)(会在后续实验中变化);
- 每个卷积层操作后保证输入输出大小不变(设置合适的填充大小以及步长为1);
- 每个池化层的核大小为\(2\times 2\times 2\),步长为
1,执行max操作,保证每次操作后输出的每个维度减少2 - 第一个池化层核大小为\(1\times 2\times 2\),一方面为了不过早合并时间信息,另一方面也是保证输入数据\(3\times 16\times 112\times 112\)符合模型定义(时间维度只能除以
4次)
- 全连接层
- 每个全连接层包含
2048个神经元
- 每个全连接层包含
- 训练
- 批量大小为
30; - 初始化学习率为
0.003; - 每隔
4轮学习率缩放10倍; - 共训练
16轮。
- 批量大小为
变化设置
论文针对时间维度的设计设置了两种方式进行实验:
- 每个卷积层拥有相同的时间维度。论文分别测试了时间维度为
1/3/5/7的网络; - 不同卷积层拥有各自的时间维度。论文测试了升序时间维度
3-3-5-5-7和降序时间维度7-5-5-3-3;
实验结果
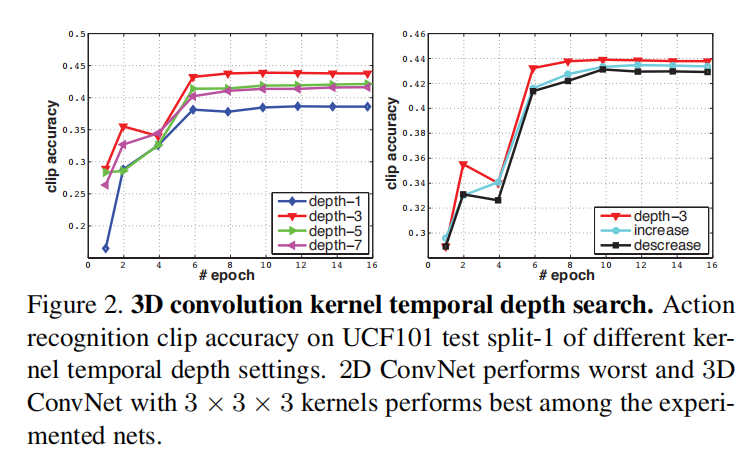
左图比较了相同时间维度下模型性能:
depth-3(也就是设置时间维度大小为3)获得了最好的性能;depth-1(也就是2D卷积网络)拥有最差的性能,表明其缺少动作建模的能力。
右图比较了变化时间维度的模型性能,从比较结果可知,保持所有卷积层时间维度相同,同时设置维度大小为3拥有最好的性能
C3D

定义
C3D拥有8个卷积层和5个池化层,跟随两个全连接层以及一个softmax输出层。整体网络架构如上图所示,其中
3D卷积核大小为\(3\times 3\times 3\),步长为\(1\times 1\times 1\);3D池化核大小为\(2\times 2\times 2\),步长为\(2\times 2\times 2\);- 第一个池化层的核大小为\(1\times 2\times 2\),步长为\(1\times 2\times 2\);
- 全连接层输出为\(4096\)维
学习内容
论文观察到C3D首先关注前几帧中的外观,然后跟踪随后几帧中的显著变化。通过反卷积方式,将conv5b两个特征图的最高激活投影回图像,可视化了C3D学习的内容

小结
C3D是最早将3D卷积作用于视频分类领域的模型之一,通过详尽的实验证明了3D卷积的有效性。