Deep Image Retrieval: Learning global representations for image search
原文地址:Deep Image Retrieval: Learning global representations for image search
官方实现:naver/deep-image-retrieval
摘要
We propose a novel approach for instance-level image retrieval. It produces a global and compact fixed-length representation for each image by aggregating many region-wise descriptors. In contrast to previous works employing pre-trained deep networks as a black box to produce features, our method leverages a deep architecture trained for the specific task of image retrieval. Our contribution is twofold: (i) we leverage a ranking framework to learn convolution and projection weights that are used to build the region features; and (ii) we employ a region proposal network to learn which regions should be pooled to form the final global descriptor. We show that using clean training data is key to the success of our approach. To that aim, we use a large scale but noisy landmark dataset and develop an automatic cleaning approach. The proposed architecture produces a global image representation in a single forward pass. Our approach significantly outperforms previous approaches based on global descriptors on standard datasets. It even surpasses most prior works based on costly local descriptor indexing and spatial verification. Additional material is available at this http URL.
我们提出了一种新的实例级别图像检索方法。它通过聚合多个区域描述符,为每个图像生成一个全局且紧凑的固定长度表示。与以前使用预训练深度网络作为黑盒来生成特征的工作不同,我们的方法利用了能够训练特定的图像检索任务的深度架构。我们的贡献有两个方面:(i)我们利用排序框架来学习卷积以及投影权重,用于构建区域特征;(ii)我们使用一个区域建议网络来判断应该将哪些区域合并以形成最终的全局描述符。使用干净的训练数据是我们的方法成功的关键。为此,我们使用了一个大规模但有噪声的地标数据集,并开发了一种自动清洗方法。所提出的架构通过单个前向计算就能够生成全局图像表示。在基准数据集上我们的方法明显优于之前的全局描述符方法。它甚至超过了大多数之前基于昂贵的局部描述符索引和空间验证的实现。额外内容公布在这里:www.xrce.xerox.com/Deep-Image-Retrieval
引言
基于深度学习的图像检索算法落后于最先进的基于局部特征的图像检索算法,最主要的原因在于用于提取卷积特征的深度模型并没有针对特定的图像检索任务进行有监督学习。之前基于CNN的检索算法通常会使用ImageNet预训练的卷积网络,卷积特征被用于分类不同的语义类别,它们对于类内变化具有相当鲁棒性。而这个属性对于实例检索而言是有害的,因为实例检索的目的就是区分特定的物体 - 即使它们属于同一个语义类别。因此,针对特定的实例检索任务进行学习是至关重要的。
论文第一个贡献:针对全局特征描述符R-MAC进行改造,将R-MAC构建为可微分的操作步骤。结合深度卷积模型和R-MAC全局特征描述符,在地标数据集上进行训练(基于三元损失函数)。因为论文使用的地标数据集来自于网络搜索,所以存在大量错标和假阳性样本。为此,论文设计了一套自动清洗流程,并且证明了干净的数据能够显著提升算法性能。
论文第二个贡献:R-MAC描述符使用固定网格进行区域特征向量创建,为此论文训练了一个区域建议网络用于替换固定网格来进行目标区域检测。通过实验证明了使用RPN进行目标检测比固定网格方式更好。
结合上述两个贡献,论文构建了一个全新架构,在单个前向计算中就可以构建得到一个固定长度的特征向量,这样图像之间通过点积计算(相似度)就可以进行比对。
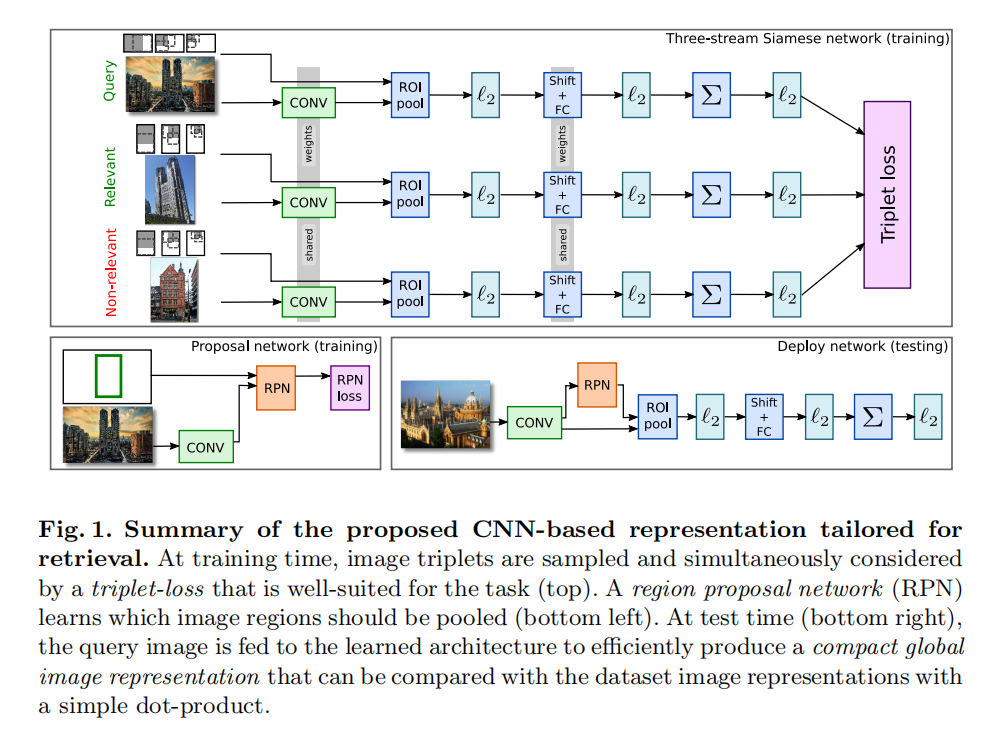
方法
回顾R-MAC
R-MAC构成如下:
- 使用预训练网络(比如
VGG16)从图像(不限大小和长宽比)中提取卷积激活特征; - 采样多尺度正方形网格(相互之间部分重叠),使用最大池化操作提取局部区域特征;
- 每个区域特征被单独的
L2归一化、PCA-白化以及再次L2归一化; - 对区域特征集合执行求和池化操作后再次
L2归一化; - 最后生成一个紧凑的短向量(通常在
256 - 512维大小)。
使用R-MAC向量进行两两点积操作计算相似度,可以近似看成多对多(many-to-many)的区域匹配。
重构R-MAC
论文对R-MAC操作进行了重构,保证每一步都是可微分的。
- 在不同区域上的空间池化操作等同于
ROI(Region of Interest)池化(不太了解,看代码); PCA投影可以看成是一个shifting操作(不太了解,还需要看代码才知道是啥操作)加上一个全连接层运算;- 最后的区域向量求和池化以及
L2归一化操作均可微分。
通过上述的改造,论文实现了一个网络架构,可以联合卷积网络以及R-MAC操作,同时进行训练优化。仅需输入图像以及预先定义好的区域坐标,就可以通过学习得到最优权重。
排序损失
假定\(I_{q}\)表示查询图像,其R-MAC描述符为\(d\);\(I^{+}\)表示真值图像,其R-MAC描述符为\(d^{+}\);\(I^{-}\)表示负样本,其R-MAC描述符为\(d^{-}\)。定义三元排序损失如下:
\[ L(I_{q}, I^{+}, I^{-})=\frac{1}{2}\max (0, m+\left\| q-d^{+} \right\|^{2} - \left\| q-d^{-} \right\|^{2}) \]
其中\(m\)是超参数,表示查询图像和真值图像之间的距离与查询图像和负样本之间的距离的边界值。
RPN
在R-MAC计算中使用了不同尺度下固定大小的正方形网格进行区域特征提取,其目的是期望感兴趣目标出现在其中一些网格中。这种均匀采样方式存在两个问题:
- 这种采样方式独立于图像内容,不太可能出现与感兴趣目标精确对齐的网格;
- 许多采样的区域仅包含了背景内容,这会影响之后的图像检索性能。
注意:这两个问题是耦合的。增加网格区域的数量可以提高覆盖率,但也可以提高不相关区域的数量。
论文使用RPN(Region Proposal Network)来直接定位感兴趣目标。在提取卷积特征的深度网络后面再训练一个全卷积网络,包含一个卷积层(\(3\times 3\)滤波器大小)以及两个同级卷积层(\(1\times 1\)滤波器大小,分别输出目标分类概率以及目标位置)。完成卷积网络计算后,使用NMS(Non-maximum suppression)进行过滤,最后得到\(k\)个候选目标。
论文尝试了同时训练R-MAC网络以及RPN,其训练很不稳定。在后续实验中,先使用固定网络采样方式训练R-MAC网络,然后固定用于特征提取的卷积网络参数,单独训练RPN。
全局描述符
通过上述方式改造,在单个前向计算中就可以获取得到一个全局描述符。
- 输入图像,生成候选区域;
- 池化候选区域内的卷积特征,投影到更有判别力的空间后进行聚合,最后执行
L2归一化;
论文在单张Nvidia K40 GPU可以每秒执行5张高分辨率图像(最大边为724像素)
噪声数据处理
。。。
实验
数据集
Oxford5k:55张查询图片(包含一个标注区域),共5062张图片;Paris6k:55张查询图片(包含一个标注区域),6412张图片;Oxford105k:Oxford5k + 100k干扰图片集;Paris106k:Paris6k + 100k干扰图片集;INRIA Holidays:500个场景,共1491张图片
评估
- 评估协议:
mAP(mean Average Precision); - 对于
Oxford5k和Paris6k数据集,- 使用查询图片中的标注区域;
- 在图库中不去除查询图片;
- 对于
Holidays数据集,使用整张查询图片,同时在图库中去除查询图片。
实验细节
- 模型:
VGG16,基于ImageNet预训练- 预处理:最短边等比缩放到
[256 - 512]区间,然后随机采样224x224大小 - 损失:排序损失,\(m=0.1\)
- 优化器:
SGD,隔\(n=64\)轮更新一次梯度 - 学习率:
1e-3 - 权重衰减:
5e-5
- 预处理:最短边等比缩放到
RPN- 权重衰减:
5e-5 - 学习率:
1e-3,每隔100k衰减10倍 - 迭代次数:
200k
- 权重衰减:
微调作用
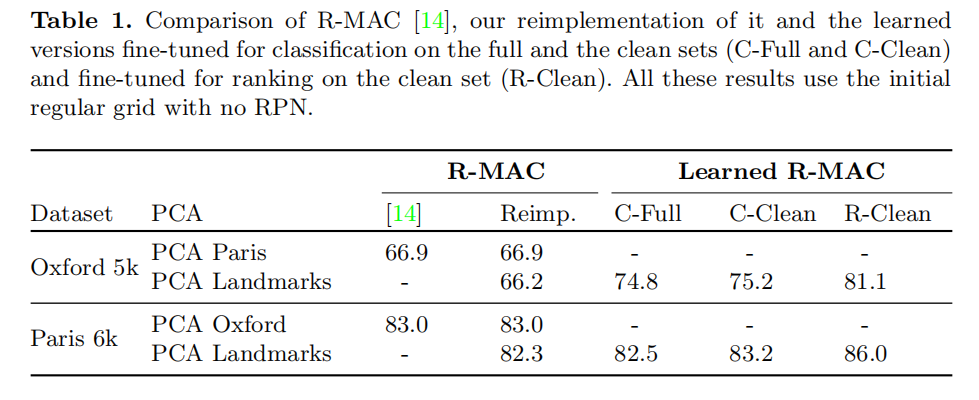
- 第一和第二列比较了原始结果以及论文复现结果;
- 论文比较了使用不同数据集学习
PCA参数的效果:- 在原始论文实现中,对于不同目标数据集,使用不一样的数据集进行学习。比如评估
Oxford5k,从Paris6k数据集中学习PCA参数,反之亦然; - 论文统一在
Landmarks数据集上进行PCA学习,从实验结果来看,相较于原始实现会略微下降性能,但是这种方式能够统一应用于所有数据集评估;
- 在原始论文实现中,对于不同目标数据集,使用不一样的数据集进行学习。比如评估
- 分类微调训练(使用交叉熵损失):基于
ImageNet预训练模型,分别在Landmarks数据集(C-Full)及其清洗版本(C-Clean)上进行分类微调训练。从结果可以发现,微调训练有助于提高检索结果,同时,清洗数据集能够帮助提升性能; - 检索微调训练(使用排序损失):结合清洗后的
Landmarks数据集(R-Clean)以及排序损失进行训练,从结果看能够有效提升性能。
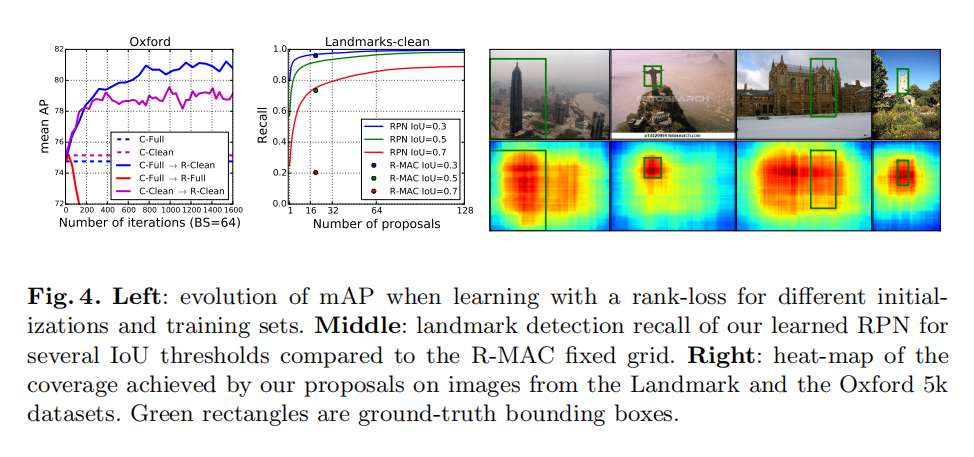
下图4左展示了不同训练设置下算法的性能,可发现,先使用C-Full进行分类训练(良好的初始参数空间),然后再使用R-Clean进行检索训练,能够最大程度的提升性能。
图像大小
对于R-MAC描述符而言,更大的输入图像有助于检索性能。论文在实验中发现,经过微调训练之后,对于1024像素和724像素大小的输入图像,在检索性能上没有差别。所以论文在后续的实验中将图像缩放(最大边)到724像素大小。
RPN评估
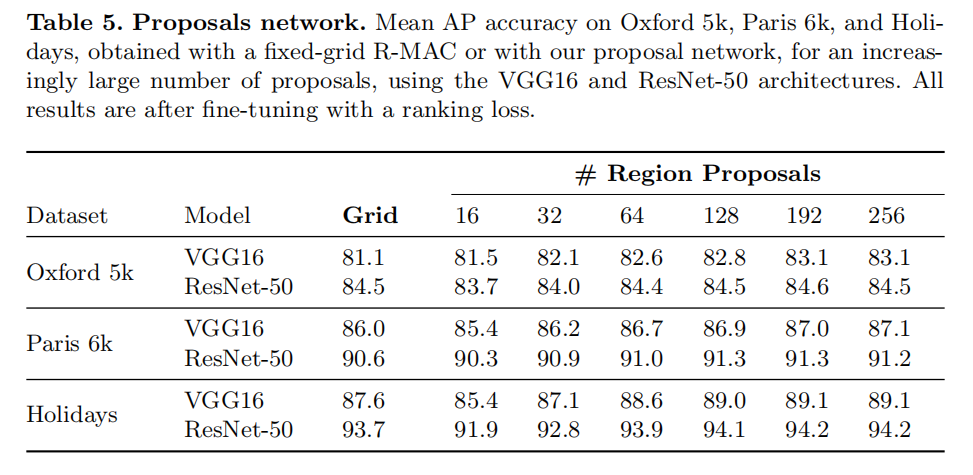
上图4中显示了在Landmarks-Clean验证集上,使用不同的IoU阈值,RPN的检测召回率与使用均匀采样策略获取的召回率策略的比较。另外相应的检索结果如下表2所示,当RPN使用超过16个候选建议后,其检索精度就超过了原始R-MAC描述符的均匀采样策略。
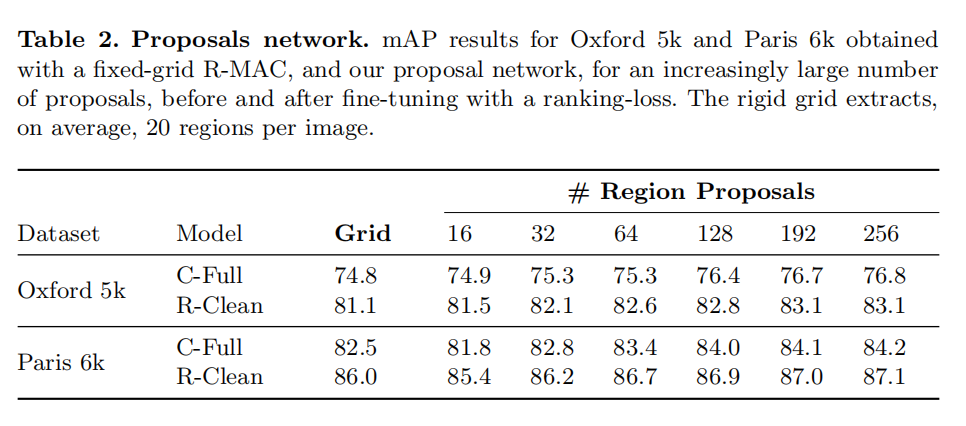
从上表中可以发现,排序损失的训练以及RPN的使用是能够互补的。在Oxford5k数据集中,将检索精度从74.8 mAP(使用C-Full分类模型 + 固定网格)提升到83.1% mAP(排序损失 + 256个候选建议)
比较SOTA
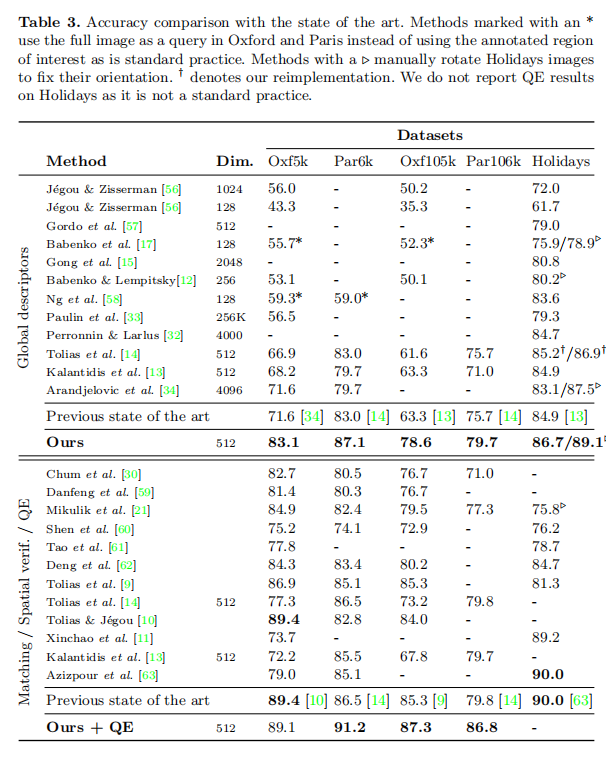
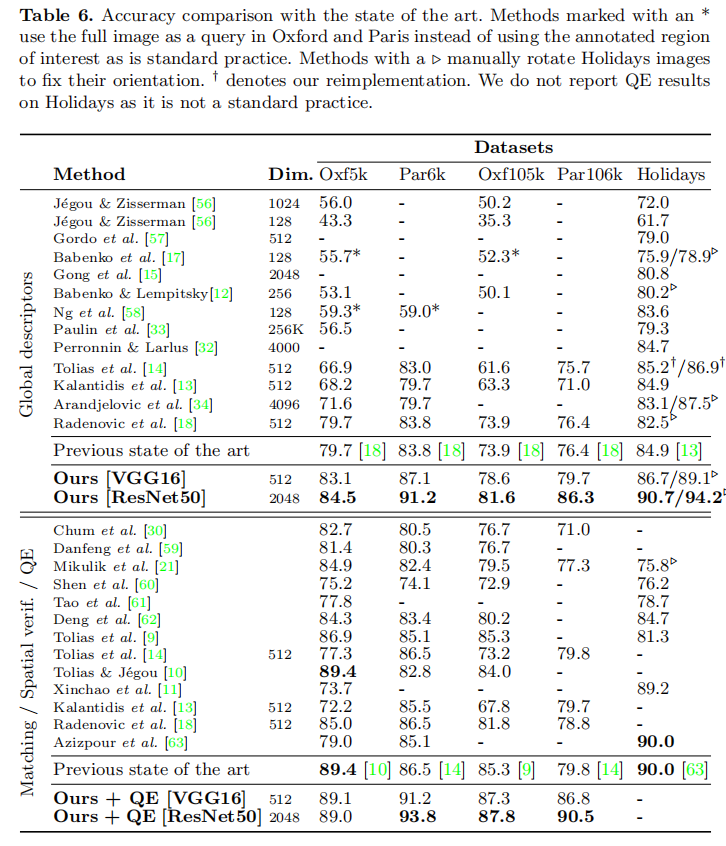
上表3中论文比较了之前最先进的图像检索算法。分两部分进行,第一部分比较了其他创建全局描述符的检索算法的性能(不执行空间矫正或者查询扩展等后处理);第二部分比较了所有最先进的图像检索算法(不一定依赖于全局描述符,可以结合后处理运算)。从上面数据中可以发现,VGG16 + 重构R-MAC + C-Full分类微调 + R-Clean 排序损失微调 + RPN(256个候选建议)+ QE能够实现最好的检索性能(512维短向量)。
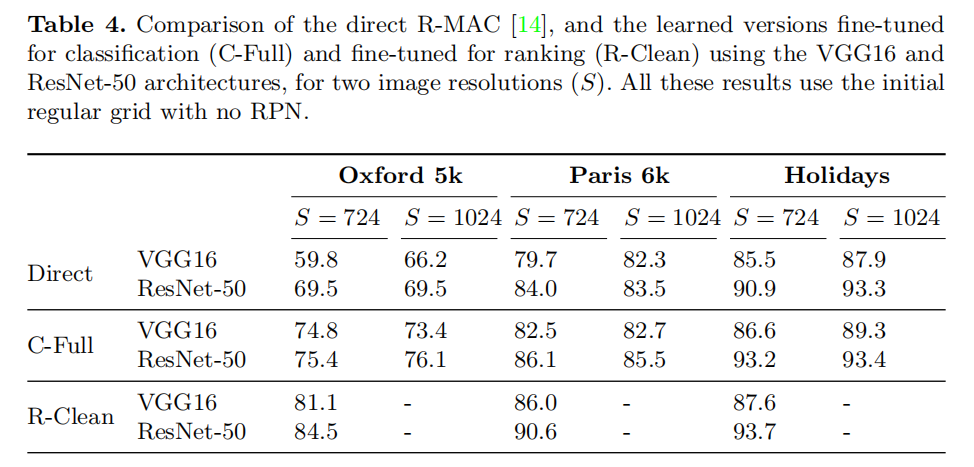
VGG16 vs. ResNet50
在上面的实现中论文使用了VGG16进行卷积特征提取,在附录中论文还测试了ResNet50的检索效果
小结
本文是一篇工程性极强的论文,通过结合当时最先进的训练策略以及模型架构,论文实现了精度和速度之间的最佳平衡。具体的优化策略包括:
- 设计可微分的
R-MAC描述符,结合卷积网络进行微调训练; - 清洗大规模噪声数据集
Landmarks; - 设计排序损失,先在
C-Full数据集上进行初始化微调训练,然后基于排序损失使用R-Clean数据集进行微调训练(这一步存疑,因为从论文描述来看在训练过程中并没有使用过多的训练技巧); - 使用
RPN模型替换R-MAC初始的均匀网络采样策略; - 最后结合
QE后处理操作进行图像检索。
很快的论文作者又针对这篇文章进行了优化,包括替换了新模型架构(ResNet)、新的特征聚合策略以及结合更多后处理算法,还比较了PCA和向量量化的影响。