Learning both Weights and Connections for Efficient Neural Networks
原文地址:Learning both Weights and Connections for Efficient Neural Networks
摘要
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To address these limitations, we describe a method to reduce the storage and computation required by neural networks by an order of magnitude without affecting their accuracy by learning only the important connections. Our method prunes redundant connections using a three-step method. First, we train the network to learn which connections are important. Next, we prune the unimportant connections. Finally, we retrain the network to fine tune the weights of the remaining connections. On the ImageNet dataset, our method reduced the number of parameters of AlexNet by a factor of 9x, from 61 million to 6.7 million, without incurring accuracy loss. Similar experiments with VGG-16 found that the number of parameters can be reduced by 13x, from 138 million to 10.3 million, again with no loss of accuracy.
神经网络是计算密集型和内存密集型的,这使得它们很难部署在嵌入式系统上。另外,传统的网络在训练开始前已经固定结构;因此,训练无法改进整个架构。为了解决这些局限性,我们描述了一种方法,通过只学习重要的连接,能够几个数量级的减少神经网络所需的存储和计算量,而且不影响其准确性。我们的方法分为三步来修剪冗余连接。首先,我们训练网络来学习哪些连接是重要的。接下来,我们删掉不重要的连接。最后,我们重新训练网络以微调剩余连接的权重。在ImageNet数据集上,我们的方法将AlexNet的参数数量减少了9倍,从6100万个参数减少到670万个,并且没有造成精度损失。在VGG-16的实验上,参数的数量可以减少13倍,从1.38亿减少到1030万,同样不损失精度。
引言
深度学习发展初期,大家还专注于开发更大参数的模型来实现更好的性能,这也约束了深度网络在嵌入式设备上的推广。论文展示了在45nm CMOS进程上进行基本运算和内存操作所耗费的能量 ,如下图所示:

- 对芯片内
SRAM进行一次32位系数访问需要5pJ; - 在芯片外
DRAM进行一次32位系数访问需要640pJ。
运行一个拥有10亿连接的网络,假定访问频率为20HZ,那么一秒钟的磁盘访问需要耗费(20Hz)(1G)(640pJ) = 12.8W,所以进行网络压缩,通过减少模型大小,将模型放置于芯片内缓存的实现具有实际意义。
3阶段剪枝
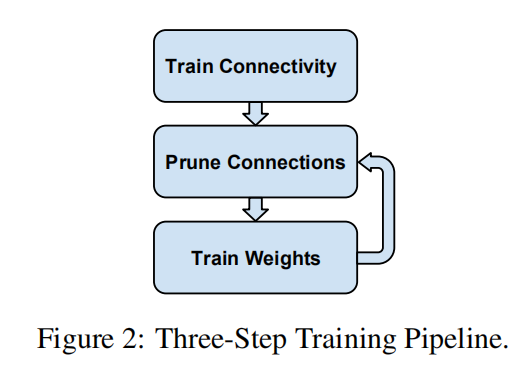
- 第一步:正常训练。学习有效的连接;
- 第二步:修剪低权重连接。使用一个全局阈值修剪权重低于该阈值的连接;
- 第三步:微调训练。恢复网络剪枝后损失的性能。
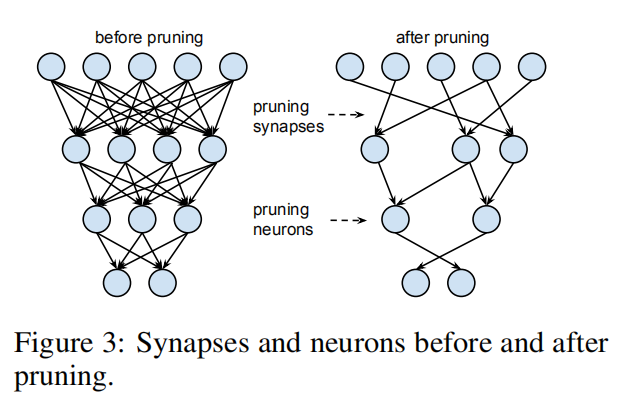
可以重复第二和第三步,通过多次剪枝-微调训练来逐步减少模型大小。另外,修剪后的网络从密集网络变成稀疏状态,如下图所示。
L1/L2正则化
论文比较了L1/L2两种正则化方法对于剪枝训练的影响,其实验结果如下图所示
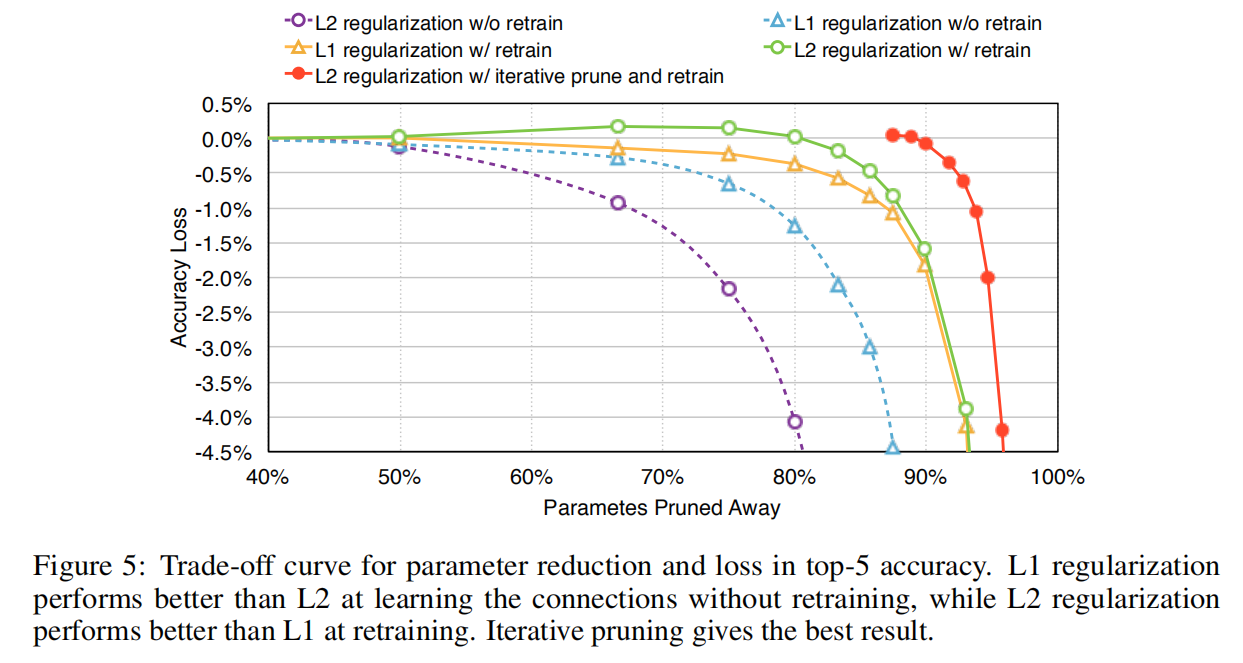
总的来说,剪枝的参数越多,损失的精度也越大。论文比较了5种剪枝环境:
- 使用
L1还是L2正则化; - 是否进行重训练;
- 交替使用
L1和L2正则化方法;
从结果上看,使用L2正则化+微调训练能够实现最佳效果
随机失活率调整
通过随机禁止某些神经元参与计算,以打乱网络内部神经元之间的协同响应,随机失活操作能够避免网络过拟合。而在剪枝之后,网络结构变得稀疏,网络将选择信息最丰富的预测器,从而具有更少的预测方差,这也减少了过拟合。所以为了得到更好的模型性能,论文提出在重训练阶段降低随机失活大小。
- \(C_{i}\)表示第\(i\)层的连接数;
- \(C_{i0}\)表示原始网络;
- \(C_{ir}\)表示重训练后的网络;
- \(N_{i}\)表示第\(i\)层的神经元个数;
第\(i\)层的连接数\(C_{i}\)由第\(i\)层和第\(i+1\)层的神经元个数决定:
\[ C_{i}=N_{i}N_{i-1} \]
重训练阶段作用于第\(i\)层的失活率\(D_{r}\)计算如下:
\[ D_{r}=D_{0}\sqrt{\frac{C_{ir}}{C_{i0}}} \]
其中
- \(D_{0}\)表示原始随机失活率;
- \(D_{r}\)表示重训练阶段的随机失活率;
- \(C_{ir}\)表示第\(i\)层剪枝后的连接数;
- \(C_{i0}\)表示第\(i\)层原始的连接数。
微调训练
论文提出在剪枝后保留剩余的参数直接进行训练,而不是重新初始化剪枝模型进行训练。因为训练得到的参数值能够加快重训练速度,同时能够实现更好的重训练精度(后面的观点在后续论文已经证明无效)。
为了避免极深网络出现的梯度消失问题,论文提出在剪枝FC层的时候固定CONV层参数进行重训练,反之依然(这也隐含了迭代训练的思路)。
迭代剪枝
一次剪枝+重训练是一轮迭代,论文推荐进行多论剪枝训练。对于AlexNet,单轮剪枝能够实现5倍的模型缩放,而进行迭代剪枝能够达到9倍的模型缩放。
实验
权重剪枝
完成训练后,逐层对低权重参数进行剪枝,设定一个全局阈值,逐层过滤绝对值权重矩阵,生成一个指示函数掩码矩阵。在网上找到一个示例,如下图所示

AlexNet/VGGNet
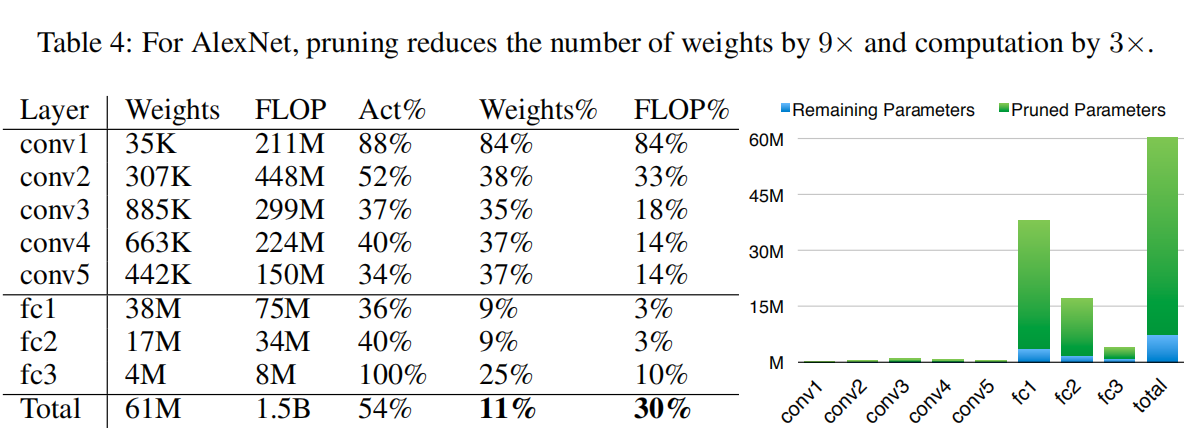
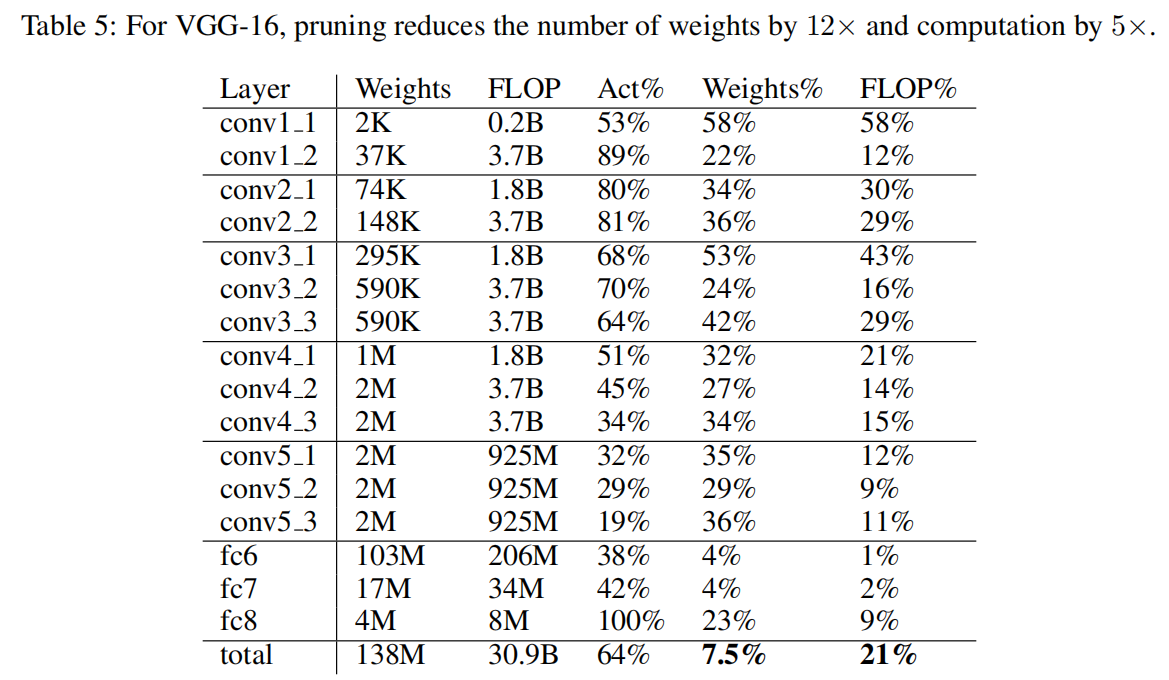
没看懂每列数值含义,反正最后一列显示AlexNet实现了9倍剪枝,VGGNet实现了12倍剪枝
逐层剪枝效果
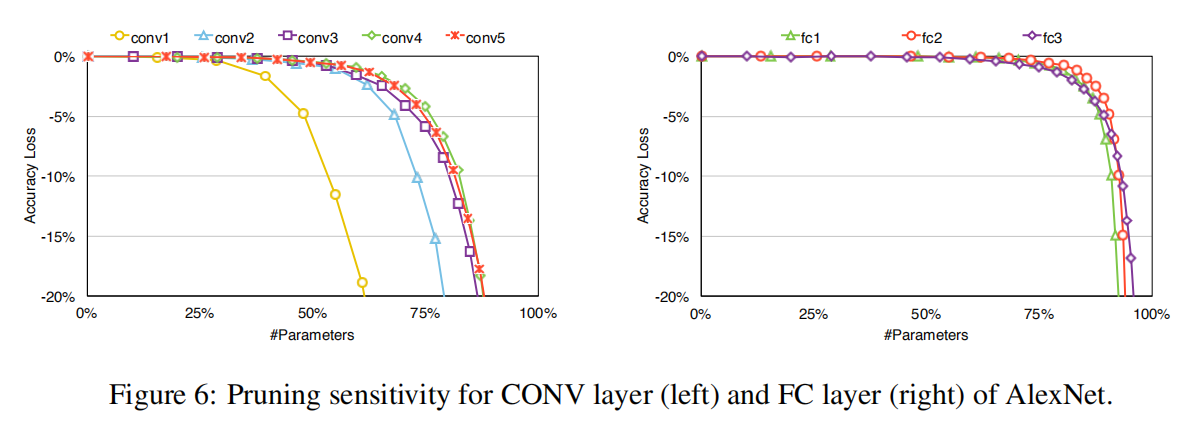
论文也比较了逐层剪枝效果,发现
- 卷积层的剪枝率小于全连接层;
- 越靠近输入的卷积层的剪枝率越低。
这一方面是因为前面的卷积层本身的参数量不大,参数冗余程度小;另一方面也说明了特征提取需要的参数空间大于目标分类。
进一步压缩
论文在结尾也提到通过稀疏矩阵方式存储剪枝层能够进一步提高压缩率;同时存储相对而非绝对索引的方式能够进一步减少存储空间(剪枝后FC层的权值索引存储仅需5位字节,CONV层权值索引存储仅需8位字节)。作者在另一篇论文Deep Compression中有详细描述
比较其他方法
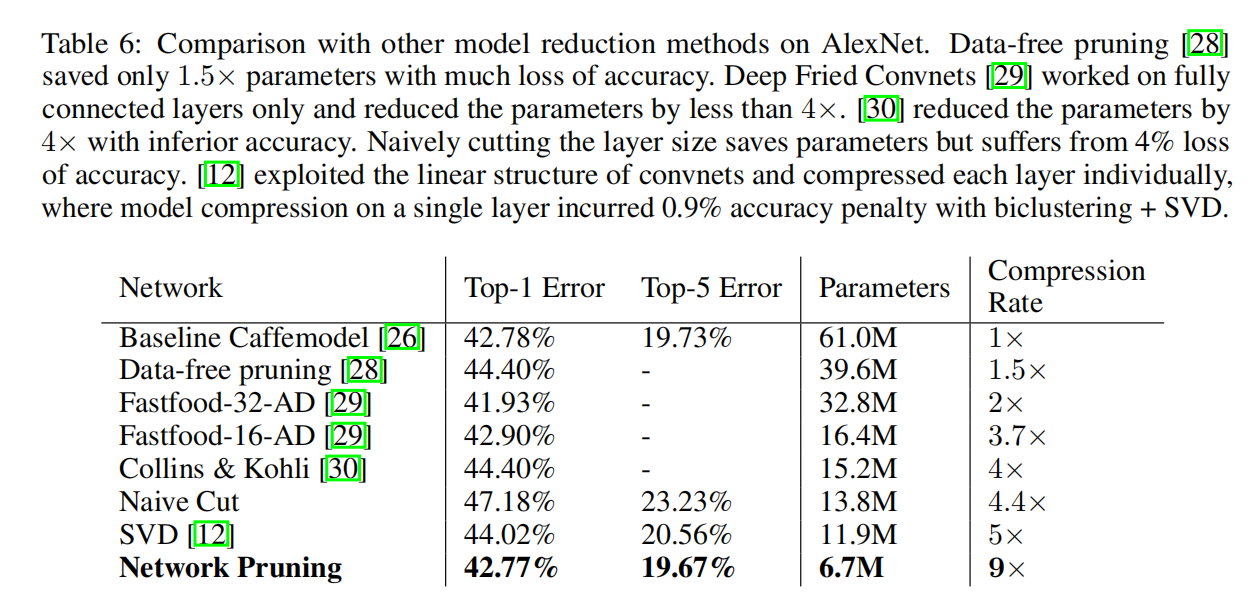
小结
这篇大概是第一个提出通过3阶段(训练-剪枝-微调)来进行网络剪枝的论文了。相对于后续论文更加关注于计算量的评估,这篇论文把关注点放在了模型大小的压缩上(估计是因为常用运算库无法加速权重剪枝方法得到的稀疏矩阵),通过减少模型的存储大小,使得深度网络能够在嵌入式设备上有更好的推广。