Combination of Multiple Global Descriptors for Image Retrieval
原文地址:Combination of Multiple Global Descriptors for Image Retrieval
官方实现:naver/cgd
摘要
Recent studies in image retrieval task have shown that ensembling different models and combining multiple global descriptors lead to performance improvement. However, training different models for the ensemble is not only difficult but also inefficient with respect to time and memory. In this paper, we propose a novel framework that exploits multiple global descriptors to get an ensemble effect while it can be trained in an end-to-end manner. The proposed framework is flexible and expandable by the global descriptor, CNN backbone, loss, and dataset. Moreover, we investigate the effectiveness of combining multiple global descriptors with quantitative and qualitative analysis. Our extensive experiments show that the combined descriptor outperforms a single global descriptor, as it can utilize different types of feature properties. In the benchmark evaluation, the proposed framework achieves the state-of-the-art performance on the CARS196, CUB200-2011, In-shop Clothes, and Stanford Online Products on image retrieval tasks. Our model implementations and pretrained models are publicly available.
图像检索任务的最近研究表明,集成不同模型的全局描述符可以提高性能。然而,训练多个模型不仅困难,而且在时间和内存方面效率低下。在本文中,我们提出一种新的框架,利用多个全局描述符来获得集成性能,同时可以以端到端的方式进行训练。该框架具有灵活性,可以扩展到不同的全局描述符、CNN主干网络、损失函数以及数据集。此外,我们定性和定量分析了组合多个全局描述符的有效性。大量实验表明,组合后的描述符性能优于单个全局描述符,因为它可以利用不同类型的特征属性。在基准评估中,提出的框架在CARS196、CUB200-2011、In-shop Clothes和 Stanford Online Products上都达到了最先进的性能。模型实现以及预训练模型已开源。
引言
论文主要贡献:
- 提出一个新的框架,是多个全局描述符的组合(
the combination of multiple global descriptors (CGD)),并且能够以端到端的方式训练; - 论文定性和定量的分析了组合多个全局描述符的影响,通过实验证明了组合描述符优于单个全局描述符,因为它们可以使用不同类型的特征属性;
- 所提出的框架在图像检索基准(
CARS196/CUB200-2011(CUB200)/Stanford Online Products(SOP)/In-shop Clothes(In-shop))上实现了最先进的性能。
架构
论文提出了一个适用于图像检索任务的框架CGD,其组合描述符由多个全局描述符连接而成,通过端到端的方式生成和学习。具体架构如下图1所示:
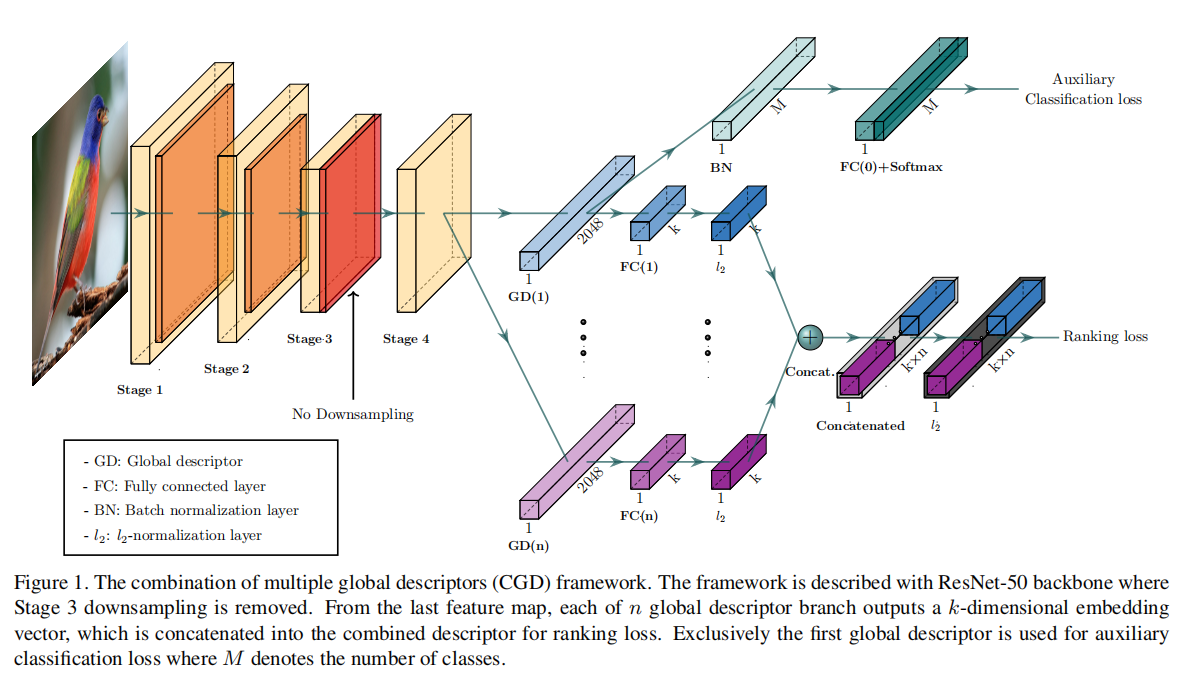
CGD由一个CNN主干网络和两个模块组成,第一个是主模块,由多个全局描述符组合而成,基于排序损失进行学习;第二个是辅助模块,通过微调分类损失进行训练。论文通过联合损失来训练整个网络,其实现由主模块的排序损失和辅助模块的分类损失求和得到。
主干网络
论文使用了ResNet-50作为主干网络,为了最后输出的特征图拥有更多的特征,论文舍弃了Stage-3和Stage-4之间的下采样操作。输入\(224\times 224\)大小,最后能够得到\(14\times 14\)大小特征图,保留了更多的特征信息。
主模块:多个全局描述符
主模块是多分支结构,从最后卷积层输出特征之后,每个分支使用不同的全局描述符生成图像表示。论文使用了三种最具表达力的全局描述符,分别是SPoC、MAC和GeM。
给定图像\(I\),最后卷积层的输出是一个3D张量\(X\),其大小为\(C\times H\times W\),其中\(C\)表示特征图个数。假定\(X_{c}\)表示第\(c\in \{1...C\}\)个特征图的集合(大小为\(H\times W\))。将\(X\)输入到全局描述符,经过池化操作后生成向量\(f\)。池化操作可以归纳如下:
\[ f=[f_{1}, ..., f_{c}, ..., f_{C}]^{T},f_{c}=(\frac{1}{\left| X_{c} \right|}\sum_{x\in X_{c}}x^{p_{c}})^{\frac{1}{p_{c}}} \]
- 当\(f^{(s)}\)表示
SPoC时,\(p_{c}=1\) - 当\(f^{(m)}\)表示
MAC时,\(p_{c}\to \infty\) - 当\(f^{(m)}\)表示
GeM时,参数\(p_{c}\)可以手动设置
对于GeM而言,参数\(p_{c}\)可以手动设置同时可以训练得到,在论文中,固定使用\(p_{c}=3\)。
第\(i\)个分支输出的特征向量\(Φ^{(a_{i})}\)还会通过全连接层进行维度衰减,同时通过L2-归一化层执行归一化操作:
\[ Φ^{(a_{i})}=\frac{W^{(i)}\cdot f^{(a_{i})}}{\left\| W^{(i)}\cdot f^{(a_{i})} \right\|_{2}}, a_{i}\in \{s, m, g\} \]
其中
- \(i\in \{1...n\}\),\(n\)表示分支数
- \(W^{i}\)表示全连接层的权重
- 全局描述符\(f^{(a_{i})}\)可以是
SPoC,当\(a_{i}=s\)MAC,当\(a_{i}=m\)GeM,当\(a_{i}=g\)
最后的特征向量是多个分支输出的组合\(\psi_{CGD}\),后续执行L2归一化操作:
\[ \psi_{CGD}=\frac{Φ^{(a_{1})}\oplus ...Φ^{(a_{i})}\oplus ...Φ^{(a_{n})}}{\left\| Φ^{(a_{1})}\oplus ...Φ^{(a_{i})}\oplus ...Φ^{(a_{n})} \right\|_{2}} \]
其中
- \(a_{i}\in \{s, m, g\}\)
- \(\oplus\)表示连接操作
论文使用In Defense of the Triplet Loss for Person Re-Identification描述的batch-hard triplet loss来训练组合描述符。
CGD的组合方式有两个优势:首先,仅需很少的参数即可完成多个全局描述符的嵌入操作;其次,每个分支可以学习到各自的特征,不需要额外的多样性控制。
辅助模块:分类损失
辅助模块基于主模块的第一个全局描述符进行分类损失微调训练。它的灵感来自于论文End-to-end learning of deep visual representations for image retrieval:先使用分类损失微调CNN主干网络,然后使用triplet loss微调训练。论文进行了优化,以端到端的方式进行训练。辅助模块的分类损失能够帮助最大化类间距离,这样可以保证模型训练更加平稳和快速。
论文对交叉熵损失进行了优化,增加了温度缩放(temperature scaling)以及标签平滑(label smoothing):
\[ L_{softmax}=-\frac{1}{N}\sum_{i=1}^{N}log\frac{exp((W_{y_i}^{T}f_{i}+b_{y_{i}}) / \tau )}{\sum_{j=1}^{M}exp((W_{j}^{T}f_{i}+b_{j}) / \tau )} \]
其中
- \(N\)表示批量大小
- \(M\)表示类别个数
- \(y_{i}\)表示第\(i\)个输入的对应标签
- \(W\)表示可训练权重矩阵
- \(b\)表示偏置向量
- \(f\)表示第一个分支的全局描述符
- \(\tau\)表示温度参数,默认为
1
架构配置
基于三个全局描述符SPoC(S)、MAC(M)、GeM(G),论文尝试了12种配置:S, M, G, SM, MS, SG, GS, MG, GM, SMG, MSG, GSM。其中,首字母对应的分支同时用于辅助模块的计算。
实验
数据集
CUB200-2011CARS196Stanford Online ProductsIn-shop Clothes
对于CUB200和CARS196,使用边界框内区域进行检索
实现
基础配置如下:
- 推理框架:
MXNet - 训练机器:
Tesla P40 GPU (24 GB内存) - 主干网络:
BN-Inception/ShuffleNet-v2/ResNet-50/SE-ResNet-50,使用MXNet GluonCV提供的预训练模型
训练阶段,
- 输入:缩放到\(252\times 252\),然后随机裁剪\(224\times 224\),以及随机水平翻转
- 优化器:
Adam,初始学习率1e-4 - 超参数\(m\):
0.1(作用于Triplet_Loss) - 超参数\(\tau\):
0.5(作用于Softmax_Loss) - 批量大小:
128
推理阶段,仅执行缩放操作(\(224\times 224\)),输出嵌入向量维度固定为1526大小
架构设计实验
联合训练分类和排序损失
辅助分类损失
论文基于数据集CARS196比较了单独排序损失和结合分类损失一起训练的结果,如下表一所示:
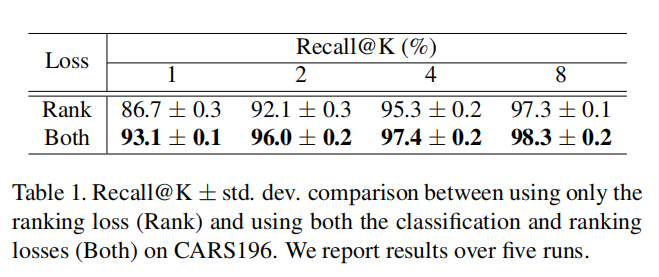
在上述实验中,仅使用标准交叉熵损失,并没有增加标签平滑和温度缩放。联合辅助分类损失进行训练有助于性能提升,论文分析:
- 分类损失侧重于在分类级别上将每个类别聚类到单独的嵌入空间中;
- 排序损失专注于收集同一细粒度类别的样本,并在实例级别中确定不同类别样本之间的距离。
因此,联合训练排序损失和辅助分类损失能够更好优化分类以及细粒度特征嵌入。
标签平滑+温度缩放
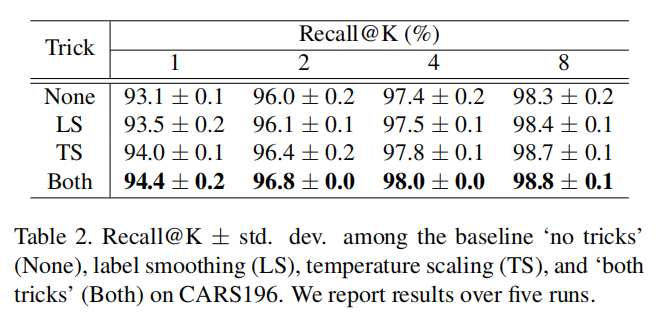
论文同样实验了标签平滑和温度缩放对于性能的影响。使用ResNet-50作为主干网络,加上全局描述符组合SM(SPoC+MAC),实现结果如下表二所示:
多个全局描述符的组合
组合的位置
论文比较了组合全局描述符的不同方式,如下图所示:
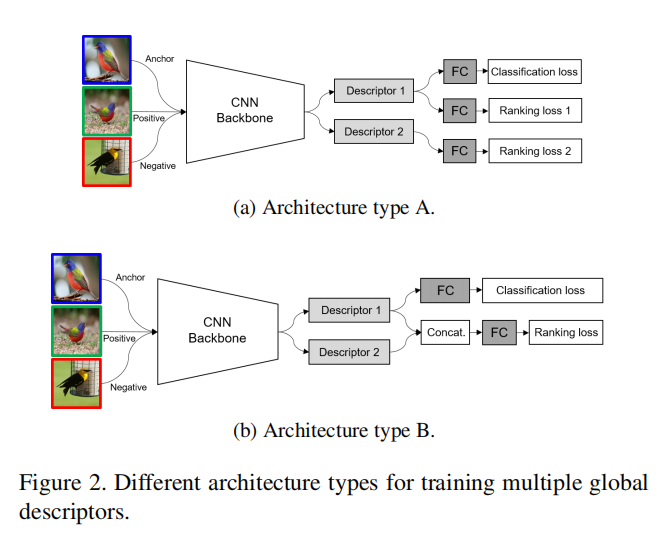
首先是使用独立的排序损失训练各个全局描述符(第一个分支还会额外训练一个分类损失);其次是将所有全局描述符组合在一起,经过FC层降维和L2归一化之后,使用一个排序损失进行训练(同样的,第一个分支会额外训练一个分类损失)。训练结果如下表所示:
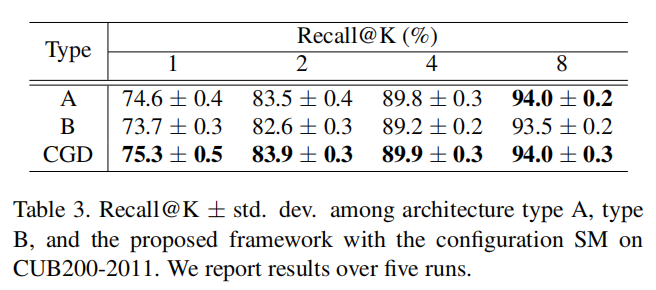
组合的方式
对于多个全局描述符组合,论文尝试了连接和求和两种方式。训练结果如下表所示:
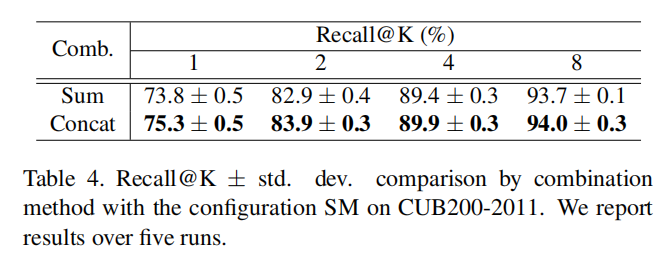
论文分析是因为连接能够最大程度的保留单个描述符的特性导致。
组合描述符的高效性
定量分析
论文实验了12种组合配置,如下图3所示:
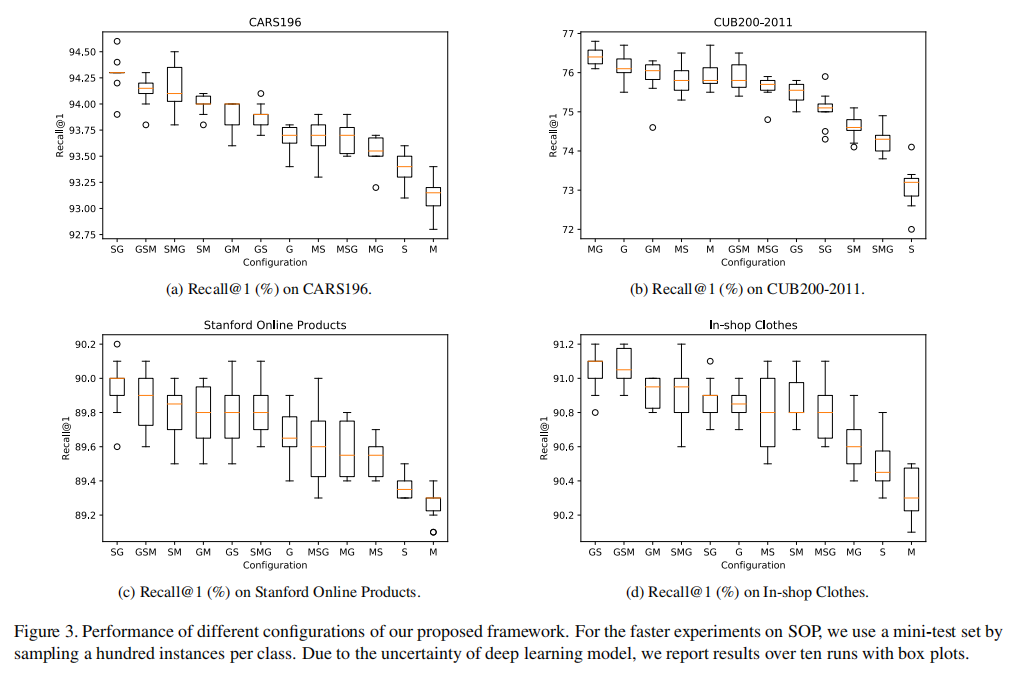
- 大多数组合描述符性能均超过了单个描述符性能;
- 最佳配置是组合最优和次优的全局描述符。
论文还在表5中详细列出了单个描述符和组合描述符的性能:
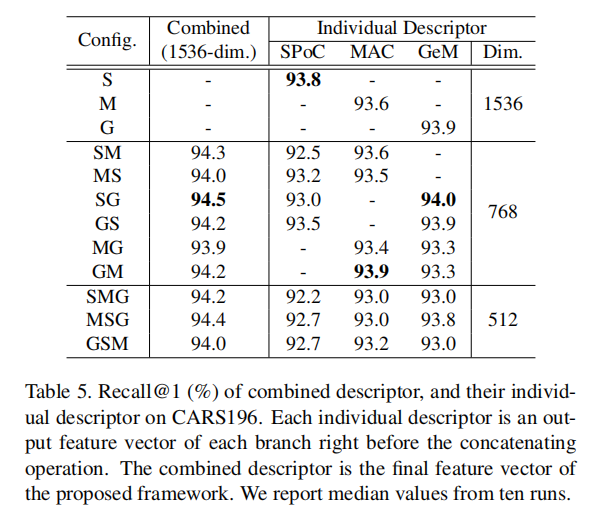
上表中描述了单个全局描述符在低维(768维)和高维(1536维),以及组合描述符(1536维)的性能。
- 更高的维度通常能够实现更好的性能;
- 当低维和高维单个描述符的性能差异不大的情况下,组合两个低维描述符能够获取更大增益。
定性分析
。。。
CGD框架灵活性
排序损失
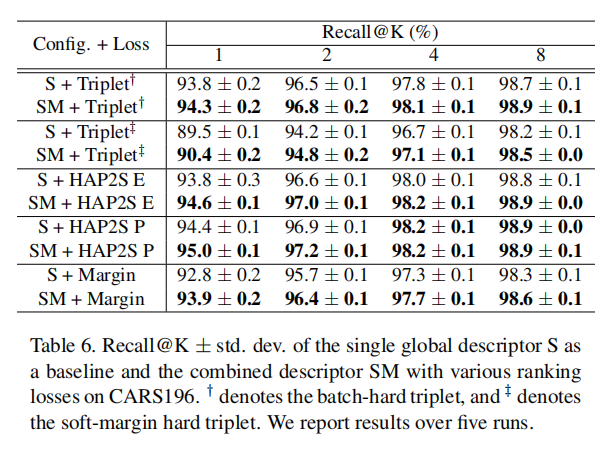
论文以SPoC为基准,比较了不同排序损失情况下S vs. SM。如下表6所示:
Backbone
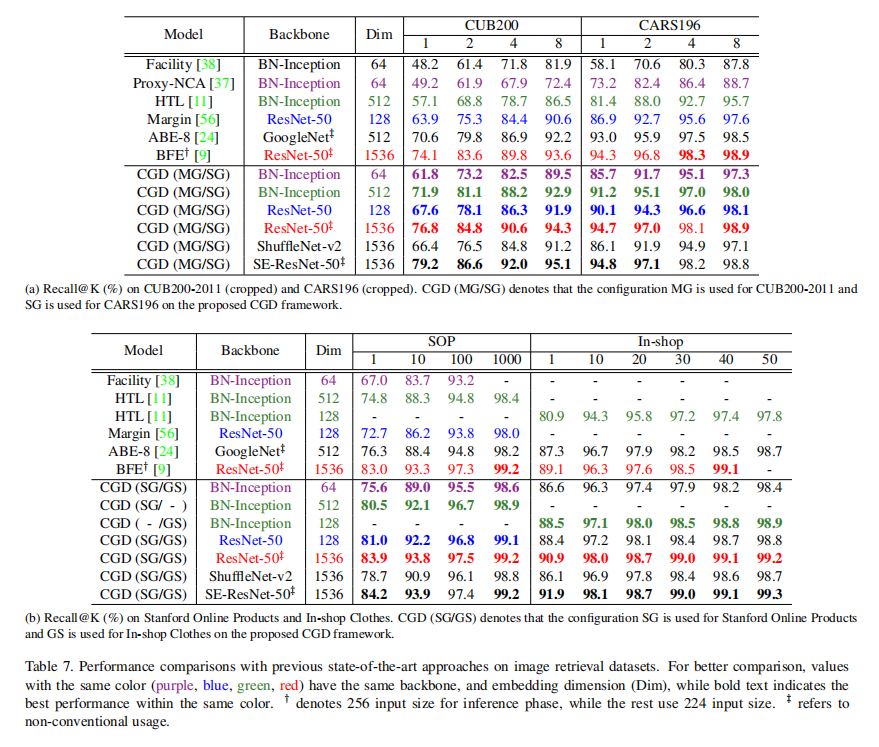
论文也尝试了不同类型的CNN Backbone,如下表7所示:
小结
论文实现了一个CGD框架,组合多个全局描述符(SPoC / MAC / GeM)以及组合多个损失(Softmax Loss / Rank Loss)参与训练,能够获取最好的检索性能。总的来说,这是一篇工程性质论文,给出了详细的实验结果以及架构配置。从实验数据来看,再一次证明了组合(combination)或者叫聚合(assemble)多个特征的方式能够有效提升性能(比对单个全局特征)。在PaperWithCode上可以发现,CGD在多个图像检索基准上实现了最优性能。
继续优化部分:
- 论文并没有提及到多个全局描述符训练效率和部署阶段的内存占用以及推理延时情况;
- 论文提供的源码库也仅提供了测试代码,并没有相应的训练代码和模型架构实现。