You Only Look Once: Unified, Real-Time Object Detection
原文地址:You Only Look Once: Unified, Real-Time Object Detection
复现地址:zjykzj/YOLOv1
摘要
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance.
YOLO是一种新的目标探测方法。先前关于目标检测的工作将分类器用于执行检测。相反,我们将目标检测作为空间分离的边界框和相关类概率的回归问题。单个神经网络在一次评估中直接从完整图像中预测边界框和类别概率。由于整个检测流程仅使用了单个网络,因此可以直接根据检测性能进行端到端优化
Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
我们的统一架构速度极快。基本YOLO模型以每秒45帧的速度实时处理图像。一个更小版本的网络,Fast YOLO,每秒处理惊人的155帧,同时仍然达到其他实时探测器的两倍mAP。与最先进的检测系统相比,YOLO的定位误差更大,但预测背景误报的可能性更小。最后,YOLO拥有目标泛化能力。当从自然图像推广到艺术作品等其他领域时,它优于其他检测方法,包括DPM和R-CNN
实现原理

- 将输入图像划分为\(S × S\)大小网格
- 每个网格预测\(B\)个边界框的坐标及置信度:
(x, y, w, h, confidence) - 同时每个网格还预测了\(C\)个条件类别概率
经过CNN模型计算后,每个网格输出\(B\times 5+C\)个向量,整个数据体大小为\(S\times S\times (B\times 5+C)\)
边界框
每个网格会预测\(B\)个边界框,每个边界框通过中心点坐标和长宽表示
置信度
置信度反映了模型对预测边界框中包含目标的置信程度,以及它认为边界框预测的准确性。其定义如下:
\[ Confidence = Pr(Object) * IoU_{pred}^{truth} \]
\(Pr(Object)\)表示该网格内是否存在目标,其判定条件为目标中心位于该网格内。如果不存在则为\(0\),如果存在则设为\(1\)
\(IoU_{pred}^{truth}\)表示预测边界框与对应真值边界框的IoU
条件类别概率
对于\(C\)个条件类别概率,其定义如下:
\[ Prob_{condition} = Pr(Class_{i} | Object) \]
条件类别概率表示网格中包含某一类别目标的概率
输出

模型输出\(S\times S\times (B\times 5+C)\)大小的数据体。每个网格输出\(B\)个边界框坐标及对应置信度,通过置信度判断得到最后的预测边界框。共有\(S\times S\)个网格,最后会输出\(S\times S\)个预测边界框,每一个都包含了对应类别和类概率
通过比较\(B\)个边界框的置信度,每个网格最终预测一个边界框,其对应的类概率计算如下:
\[ Pr(Class_{i} | Object) * Pr(Object) * IoU_{pred}^{truth} = \ Pr(Class_{i}) * IoU_{pred}^{truth} \]
之后再通过概率阈值以及NMS方法进行过滤,得到最后的目标检测和分类结果
超参数设置
有3个超参数:
S:网格数。从实现上看,每个网格仅预测单个目标。也就是说,每个网格应该仅包含单个真值边界框(Ground Truth)B:预测边界框个数C:条件类别概率。其通过训练数据集的类别数确定
对于PASCAL VOC 2007数据集,设置S=7, B=2, C=20
CNN模型
参考GoogLeNet模型实现了一个24层卷积的网络

同时还设计了一个Fast YOLO模型,仅包含9层(没有找到实现)
针对PASCAL VOC数据集,网络最后输出\(7\times 7\times 30\)大小数据体
损失函数
为了有效计算目标检测以及分类,论文设计了一个复杂的损失函数:Multi-Part Loss。计算了多个属性之间的平方和误差(sum-squared error):
- 预测边界框坐标(\(x/y/w/h\))和真值边界框坐标(\(\hat{x}/\hat{y}/\hat{w}/\hat{h}\))
- 预测边界框的置信度(\(C\))和真值边界框的置信度(\(\hat{C}\))
- 每个网格的条件类别概率(\(p_{i}(c)\))以及真挚边界框的条件类别概率(\(\hat{p_{i}}(c)\))
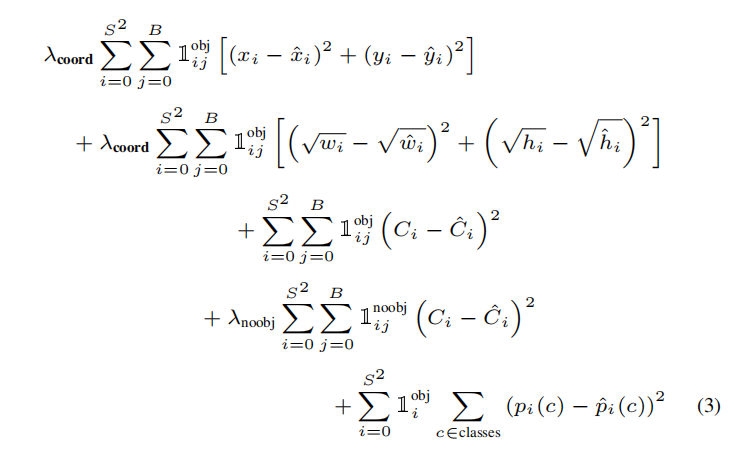
在训练过程中,计算每个网格的预测边界框与真值边界框的\(IoU\),设置\(IoU\)最大的为该网格输出。与此同时,真值边界框的置信度以及对应类别概率设置\(1\),其他类别概率设为\(0\)
注意:GT的中心位于哪个网格内,那么由该网格负责预测这个GT。如果网格存在目标,那么计算输出预测框和真值边界框的坐标、置信度以及条件分类概率的损失;对于其他预测边界框,仅计算置信度损失。使用以下函数进行控制
- \(1_{ij}^{obj}\):示性函数。如果网格\(i\)的第\(j\)个预测边界框作为网格的输出,则设为\(1\);否则设为\(0\)
- \(1_{ij}^{noobj}\):示性函数。和\(1_{ij}^{obj}\)作用相反,如果网格\(i\)的第\(j\)个预测边界框不作为输出,那么设为\(1\),否则设为\(0\)
- \(1_{i}^{obj}\):示性函数。如果网格\(i\)存在真值边界框,那么设为\(1\),否则设为\(0\)
论文还进行了如下设置:
- 为了更好的平衡定位误差和分类误差,分别使用了超参数\(\lambda_{coord}\)和\(\lambda_{noobj}\),分别设置为\(5\)和\(0.5\)
- 为了更好的反映小边界框的变化,使用宽/高的平方根进行误差计算
训练
在ImageNet 1000类数据集上进行预训练,使用前20个卷积层,然后通过全局平均池化层和全连接层进行分类。在ImageNet 2012验证集上得到top-5 88% 。此时输入图像大小为224 x 224
在PASCAL VOC数据集上
- 对于边界框表示,使用中心点坐标以及长宽。其中
- 使用图像长宽归一化边界框长宽,取值为
(0, 1) x/y坐标设置为所在网格的偏移,同样取值为(0, 1)
- 使用图像长宽归一化边界框长宽,取值为
- 除了最后一层(当前使用
Sigmoid),其他层操作后执行leaky ReLU
\[ \phi (x) = \left\{\begin{matrix} x & if x > 0 \\ 0.1x & otherwise \end{matrix}\right. \]
训练参数
- 输入图像:
448 x 448 batch: 64momentum: 0.9weight decay: 5e-4- 随机失活:
0.5,第一个全连接层 - 数据增强:相比于原始图像大小
20%的随机缩放和平移。在HSV颜色空间中,对图像的曝光和饱和度随机调整1.5倍
优缺点
优点
单个卷积网络同步的预测边界框和对应的类概率。相比于传统检测系统的优势:
- 速度快。将检测问题看成回归问题,不需要复杂的流水线操作
YOLO对整个图像进行处理预测,能够结合上下文进行检测,所以对于背景错认几率远小于Fast R-CNNYOLO的泛化能力更强
缺点
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
YOLO对边界框预测施加了很强的空间约束,因为每个网格单元只能预测两个框,并且只能有一个类。这种空间限制限制了我们的模型可以预测的附近目标的数量。对于成群出现的小对象(如鸟群)而言效果不佳
Since our model learns to predict bounding boxes from data, it struggles to generalize to objects in new or unusual aspect ratios or configurations. Our model also uses relatively coarse features for predicting bounding boxes since our architecture has multiple downsampling layers from the input image.
由于我们的模型学习从数据中预测边界框,所以它很难推广到新的或不寻常的宽高比或配置中的目标。并且模型还使用相对粗糙的特征来预测边界框,因为我们的架构有来自输入图像的多个下采样层
Finally, while we train on a loss function that approximates detection performance, our loss function treats errors the same in small bounding boxes versus large bounding boxes. A small error in a large box is generally benign but a small error in a small box has a much greater effect on IOU. Our main source of error is incorrect localizations.
最后,当训练一个接近检测性能的损失函数时,我们的损失函数对待小边界框和大边界框中的误差是一样的。大边界框里的小误差通常是可接受的,但小边界框的小误差对IOU的影响要大得多。我们的主要错误来源是定位错误
YOLO vs. Fast R-CNN
在PASCAL VOC 2007数据集上比较YOLO和Fast R-CNN的表现。每次预测分类如下:
- 完全正确(
Correct):分类正确同时IoU>0.5 - 定位不准(
Locatization):分类正确同时0.1 < IoU < 0.5 - 分类相似(
Similar):分类相似同时IoU > 0.1 - 其他(
Other):分类错误,IoU > 0.1 - 错分为背景(
Background):IoU < 0.1

从图中发现,YOLO算法的定位更加准确,同时Fast R-CNN的背景错分概率是YOLO的3倍
PyTorch实现
自定义了YOLO_v1实现,参考:zjZSTU/YOLO_v1
相关链接
以下博客对YOLOv1的理解很有用