WIDER FACE: A Face Detection Benchmark

摘要
Face detection is one of the most studied topics in the computer vision community. Much of the progresses have been made by the availability of face detection benchmark datasets. We show that there is a gap between current face detection performance and the real world requirements. To facilitate future face detection research, we introduce the WIDER FACE dataset, which is 10 times larger than existing datasets. The dataset contains rich annotations, including occlusions, poses, event categories, and face bounding boxes. Faces in the proposed dataset are extremely challenging due to large variations in scale, pose and occlusion, as shown in Fig. 1. Furthermore, we show that WIDER FACE dataset is an effective training source for face detection. We benchmark several representative detection systems, providing an overview of state-of-the-art performance and propose a solution to deal with large scale variation. Finally, we discuss common failure cases that worth to be further investigated. Dataset can be downloaded at: http://shuoyang1213.me/WIDERFACE/
人脸检测是计算机视觉领域研究最多的课题之一。人脸检测基准数据集的可用性已经取得了很大进展,但是我们发现当前的人脸检测性能与现实世界的要求之间仍旧存在差距。为了促进未来的人脸检测研究,我们引入了比现有数据集大10倍的WIDER FACE数据集。该数据集包含丰富的标注内容,包括不同的遮挡、姿势、事件类别和面部边界框。如图1所示,由于尺度、姿态和遮挡的巨大变化,所提出的数据集中的人脸极具挑战性。另外,我们还证明了WIDER FACE数据集是人脸检测的有效训练源。我们对几种具有代表性的检测系统进行了基准测试,概述了最先进的性能,并提出了一种应对大尺度人脸变化的解决方案。最后,我们讨论了值得进一步研究的常见故障案例。数据集下载:http://shuoyang1213.me/WIDERFACE/
概述
论文把人脸的变化总结为6个因素,分别是大小、姿势、遮挡、表情、外观和照明条件(scale, pose, occlusion, expression, appearance and illumination),如下图所示。

WIDER FACE是一个人脸检测数据集,一共有32203张图片以及393703张人脸标注,这些人脸数据在大小、姿势和遮挡方面存在非常丰富的变化。WIDER FACE将人脸划分为61个事件类别,对于每个类别,随机采样40%/10%/50% 作为训练/验证/测试数据集。
属性
论文首先使用EdgeBox,参考KITTI和MALF数据集的评估标准将数据集划分为3个难度:Easy/Medium/Hard,然后比较EdgeBox在不同数据集上的检测率(平均召回率)来证明WIDER FACE的挑战难度。接下来论文利用上面的检测结果对人脸不同属性进行分析,比如对于人脸大小属性(Scale),结合EdgeBox检测性能和人类感知将数据集划分为3个尺度:
- small:目标高度在10-50像素之间;
- medium:目标高度在50-300像素之间;
- large:目标高度在300像素以上。
与此类似的还有遮挡属性(Occlusion)、姿态属性(Pose)以及针对不同场景人脸的困难度(Event)划分。如下图所示:
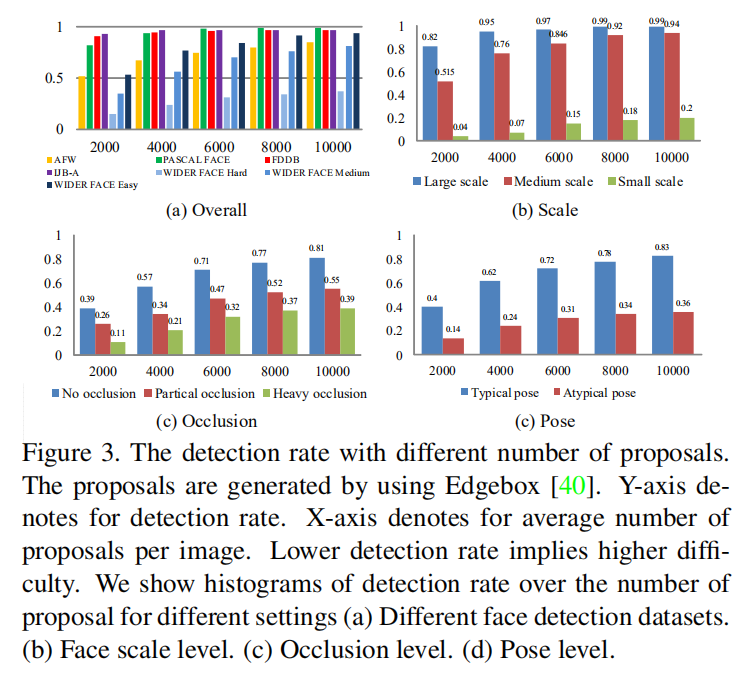
小结:这个章节我不太理解,我能想到的是作者希望论证WIDER FACE是一个充满挑战性,能够模拟真实世界不同场景人脸情况的数据集,所以会列出各种维度的评估结果。但是论文并没有具体描述使用的评估方法,评估流程和标准,所以阅读下来很难抓住论文重点。
数据集
论文在官网提供了WIDER FACE人脸数据集的下载源,另外目前常用的是结合5点人脸关键点标注的WIDER FACE数据集,具体标注文件和解析脚本可以参考:zjykzj/YOLO5Face
未找到相关的 Issues 进行评论
请联系 @zjykzj 初始化创建